Git lesson 6: introduction to branches

In previous lessons, we learned about the key aspects of the Git workflow:
- make changes -> stage changes -> commit changes
This basic workflow is appropriate in many circumstances. However, there are situations where you want to keep a working version of your project and make changes to your files. This is where Git branches come in!
Why we need Git branches: a simple example
Let’s say you finished writing a computer program called program.py that imports and processes the data from your recent experiment. You know this program works because you have inspected its output when it processed a file of test data you created. After processing data from the first few subjects, you and your supervisor discuss your next experiment and you realize you need to make some modifications to your code to account for several new measures.
What are some ways you could modify your code to use it for this next experiment? Let’s consider three options.

Option 1.
Option 1. As outlined in the above figure, you could make a copy of your current project in a new folder (1) and start modifying the code to meet the needs of the next experiment (2). Most of the code does not need to change; you are adding functionality to your previous program by adding new code and only making minor changes to the original code. The problem with this option is you will end up having the same code in two places, but this violates one of the key tenants of good coding: DRY (Don’t Repeat Yourself). Let me explain why having similar code in more than one place is a bad idea. Imagine you start working on the code for your new project and you find a major bug (i.e., a glitch in your computer program) that introduces an error when there is a missing data point. You obviously want to fix the bug in the code for the next experiment (3), but you also need fix the bug in the code for the current experiment (4). Given that bugs happen more often than we would like to admit, you will come across many more bugs as you write the program for your next experiment (5, 6, 7). That means you also have to make the same changes in the code for the current experiment.
Having to make identical changes in two places is error prone because eventually you will make a change to one version of the file but not the other; you can literally go mad trying to find these types of mistakes (8)!
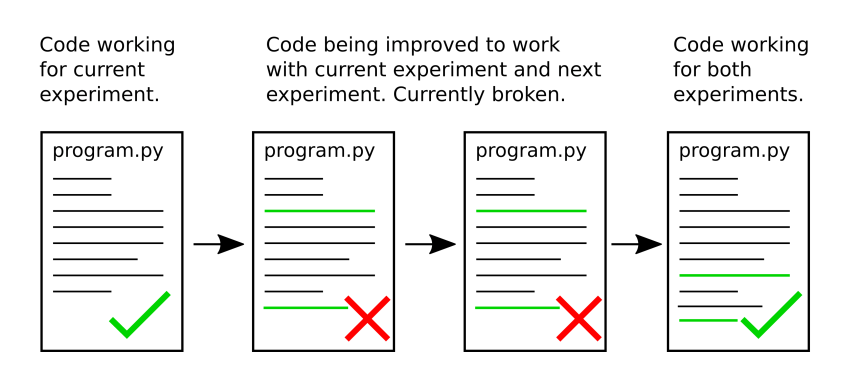
Option 2.
Option 2. As outlined in the above figure, you could keep only one copy of the code by directly modifying the code for your current experiment so that it also works with data from the next experiment. The problem with this approach is that your code will be broken until you finish the new version of your program. This means you won’t be able to process data for your current experiment or the next experiment until you have finished your code.

Option 3.
Option 3. As outlined in the above figure, wouldn’t it be great if you could take your program and work on it in an alternate universe (1) without affecting the working version of your program in the real world? Once you completed the code in this alternate universe (2), you could teleport the code back to the real world (3). With this type of workflow, the working version of your code would always be available for use (i.e., it will be functional and not broken). You can actually do this with Git! But don’t be disappointed when I tell you it doesn’t involve alternate universes.
In Git, we achieve this functionality with branches.
Summary
Hopefully you have a better idea of what branches are for in Git and why you might use them. There are many more ways branches can be used and some of these will be discussed in future lessons. For now, try to understand the difference between the three options presented above, and in the next lesson you will make your first branch!
