Cohen’s d: a standardized measure of effect size

Various tools, scales and techniques are available to researchers to quantify outcome measures. Some of these tools are familiar, like a weight scale to measure weight loss over the course of an exercise program. Others are less familiar and are only understood by those working in the same field. Furthermore, different outcome measures can be calculated from the same data. For example, the size of motor evoked potentials, elicited by a brief magnetic pulse delivered to the brain, can be reported in terms of peak-to-peak amplitude or the area under the curve. These values can be expressed in original units — mili or microvolts — or as a percentage of a baseline value or an evoked maximal response.
The above observations raise two important questions:
- How can we interpret the size of published effects if we are not familiar with the measures?
- How can we compare results from studies using different measures?
One approach is to calculate a standardized measure of effect size.
Effect size measure
The effect size measure we will be learning about in this post is Cohen’s d. This measure expresses the size of an effect as a number standard deviations, similar to a z-score in statistics.
The basic formula to calculate Cohen’s d is:
d = [effect size / relevant standard deviation]
The denominator is sometimes referred to as the standardiser, and it is important to select the most appropriate one for a given dataset.
Calculating Cohen’s d for two independent groups
Let’s calculate Cohen’s d for an effect between two independent groups. If we assume that the variance is homogeneous between groups, we can use the pooled standard deviation between groups as our standardiser.
The formula to calculate the pooled standard deviation is:
![SDpooled = \sqrt{\dfrac{[(n_1 - 1) \times (SD_1)^2] + [(n_2 - 1) \times (SD_2)^2]}{n_1 + n_2 - 2}}](https://s0.wp.com/latex.php?latex=SDpooled+%3D+%5Csqrt%7B%5Cdfrac%7B%5B%28n_1+-+1%29+%5Ctimes+%28SD_1%29%5E2%5D+%2B+%5B%28n_2+-+1%29+%5Ctimes+%28SD_2%29%5E2%5D%7D%7Bn_1+%2B+n_2+-+2%7D%7D&bg=ffffff&fg=111111&s=0&c=20201002)
Where 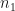



The effect size 

Figure 1: Simulated distribution of two independent groups, with the mean values highlighted.

The formula to calculate Cohen’s d is simply:
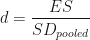
Example
In a previous post we analysed simulated data (see figure below). Briefly, we created a dataset relating to the the environmental impact (measured in kilograms of carbon dioxide) of pork and beef production. The data was sampled from 30 cows and 30 pigs.
Figure 2: Grey dots represent each animal in our sample. The means and standard deviations are also plotted.

We might want to compare environmental impact in this dataset (measured in kilograms of carbon dioxide) to another study that measured environmental impact using a different measure with different units (e.g. Joules per hour). To make the outcome measures comparable, we can compute Cohen’s d.
The mean value for beef is 353.6 whereas it is 262.0 for pork. So the effect size in original units is 91.6 kilograms of carbon dioxide. We will calculate the pooled standard deviation between pork and beef to use as our standardizer:
![SDpooled = \sqrt{\dfrac{[(n_{beef} - 1) \times (SD_{beef})^2] + [(n_{pork} - 1) \times (SD_{pork})^2]}{n_{beef} + n_{pork} - 2}}](https://s0.wp.com/latex.php?latex=SDpooled+%3D+%5Csqrt%7B%5Cdfrac%7B%5B%28n_%7Bbeef%7D+-+1%29+%5Ctimes+%28SD_%7Bbeef%7D%29%5E2%5D+%2B+%5B%28n_%7Bpork%7D+-+1%29+%5Ctimes+%28SD_%7Bpork%7D%29%5E2%5D%7D%7Bn_%7Bbeef%7D+%2B+n_%7Bpork%7D+-+2%7D%7D&bg=ffffff&fg=111111&s=0&c=20201002)
![SDpooled = \sqrt{\dfrac{[(30 - 1) \times (140.7)^2] + [(30 - 1) \times (157.2)^2]}{30 + 30 - 2}}](https://s0.wp.com/latex.php?latex=SDpooled+%3D+%5Csqrt%7B%5Cdfrac%7B%5B%2830+-+1%29+%5Ctimes+%28140.7%29%5E2%5D+%2B+%5B%2830+-+1%29+%5Ctimes+%28157.2%29%5E2%5D%7D%7B30+%2B+30+-+2%7D%7D&bg=ffffff&fg=111111&s=0&c=20201002)
Having calculated the effect size and the pooled standard deviation, we can now calculate Cohen’s d:

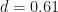
Summary
In this post we learned about measures of standardized effect size, in particular Cohen’s d. We applied what we learned to data from a previous example and found that the difference in environmental impact between beef and pork is approximately 0.6 standard deviations. What is nice about this value is that it can be compared to d values calculated using other measures of environmental impact. For example, it might be hard to compare results reported in units of kilograms of carbon dioxide to those reported in units of Joules per hour. However, if we computed that Cohen’s d for the first study was 0.33 and the second was 0.36, we could conclude that the reported effects are similar in sizes.
In our next post we will discuss how to interpret Cohen’s d. Is 0.6 a big or a small effect? We will also discuss the choice of an appropriate standardizer.

A great explanation on Cohen’s d! How can we cite this in a reference list?
LikeLike
In-text citation:
Héroux (2017) or (Héroux, 2017)
References:
Héroux M. (2007, June 29). Re: Cohen’s d: a standardized measure of effect size. Scientifcally Sound. https://scientificallysound.org/2017/06/29/cohens-d-and-effect-size/
LikeLiked by 1 person
very easy to understand, good explanation!
LikeLike
Certainly. Just reference the blog post when you use the figure. And thanks for asking for permission!
LikeLike
Absolutely, full credit and linked directly to your blog. Thanks again!
Marc
LikeLike
Thank you for this post, would I be able to use your “Figure 1: Simulated distribution of two independent groups, with the mean values highlighted.” for a paper I have written and would like to submit to a journal? called “INVESTIGATION OF EXPERIENTIAL LEARNING
PRACTICES IN K-12 EDUCATION” Properly citing your work of course.
Sorry I couldn’t find any contact info other than this post?
LikeLike