Simple linear regression

Linear regression is one of the most versatile tools in the data analyst’s toolbox. While it can get quite complicated, simple linear regression is rather intuitive and straightforward.
In this post we will look at a small dataset so that we can work through and visualise the logic of linear regression. A bigger version of this dataset will be used in our next post where we will learn how to compute a linear regression using the R statistical programming language.
The simplest model: the mean
The simplest model we can come up with is that, for any value of our predictor variable (i.e. density of the wine), the outcome variable will have a value equal to the mean of all outcomes variables (i.e. alcohol content of the wine).
The top part of the figure shows a scatter plot of our data fitted with our simple model. The line is close to some points, but far from others. Overall, it is not a great fit. Because this is the simplest model possible, it serves as the comparison for all other models.
As we will see in the next section, we assess how well other models fit our data by determining how much of the total variance they account for. The total variance (variability) is actually the variance associated with the simplest model.
The bottom part of the figure shows, for each data point, the error associated with the simplest model. The length of the red dashed lines represent the size of these errors. We determine the total variance by computing the total sum of squares (
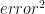

The method of least squares: the best linear model
We can use statistical programs such as R to calculate the line of best fit for our data. While the mathematical details of how R determines the line of best fit is beyond the scope of this blog post (and the capabilities of my puny brain), know that R uses the method of least squares. As its name implies, the method of least squares iterates to find the line associated with the smallest sum of squares. Put simply, it finds the line that results in the smallest possible value when we square each of the errors (i.e. the dashed red lines from the figure above) and sum them.
The method of least squares finds the line of best fit, but this does not mean it is necessarily a good fit. How can we tell if our model is a good fit? We can determine how much of the total variance (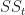
The figure below shows the line of best fit determined by the method of least squares. Again, the bottom part of the figure shows the error associated with our model. As we can see, our new model is a much better fit; the errors between the data points and our model (dashed red lines) are shorter. Despite being a good fit, there is some variance associated with our model. How much? We can determine this by computing the residual sum of squares: 
Previously we saw that the total variance (i.e. 
We can determine the proportion of improvement due to the model by calculating 

Is my model statistically significant? You might be interested in knowing whether the overall fit of your model is statistically significant. We can do this with an F-test, which uses the sum of squares we have calculated. Test statistics like the F-test consider the amount of systematic variance divided by the amount of unsystematic variance. Put another way, test statistics compare the model against the error in the model.
The F-test is based on the ratio of the improvement due to the model (
The mean square associated with 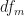
The mean square associated with 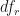
For the current example:


We can now determine the F-ratio:
F =
F = 14.57 / 0.325
F = 44.88
By consulting a table of critical values for the F distribution, we see that for degrees of freedom (1, 8) the critical value is 5.32 for p=0.05 and 11.26 for p=0.01. Statistical software will even provide us with an exact p-value, which is our case is p=0.0001528. Thus, we can conclude that our model is statistically significant.
Summary
In this post we learned about simple linear regression and how we can assess our models. In the next post, we will learn how to perform simple linear regression in R.

MARTIN! My hero! Thank you!! I am studying for an intro to statistics final and just couldnt wrap my head around total sum of squares / residual sum of squares / model sum of squares but thanks to you it finally clicked 🙂
LikeLike
Can you send me the CSV file of the data you are using here?
LikeLike
Thanks for you interest in this post. In a subsequent post I link to the full dataset from which I sampled the few data points used for demonstration purposes here. The link is: https://github.com/MartinHeroux/ScientificallySound_files/blob/master/white.csv
LikeLike