Understanding interaction (subgroup) analysis in randomised studies

When we try to interpret findings from a study, we often like to understand whether an effect (of a treatment or test condition) might be different in subjects with different characteristics. If there was substantial variability among subjects, this may have masked a treatment effect in a select few. How can we understand effects in select groups of subjects that our study was not necessarily powered to detect? In a recent review, clinical epidemiologists Brankovic and colleagues explain the motivation for such analysis, the theory behind how to conduct them, and practical implications of interpreting them.
Background
When a treatment effect is different in subjects with different baseline characteristics, investigators say that a (statistical) interaction is present. For example, if balance exercises to reduce falls are more effective in people who are strong, compared to those who are weak, we say there is an interaction between balance exercise and muscle strength.
In randomised controlled trials, analysing the effects of treatment in groups of subjects with different characteristics is known as a subgroup analysis. Investigators are interested in subgroup analysis to understand how the treatment can be used more effectively by identifying who benefits the most, or who is at most risk of harm. Interaction effects in randomised controlled trials are specified as secondary aims, however incorrect testing or interpretation may cause unnecessary withholding of treatment, ineffective treatment, or harm.
Assessing statistical interactions
A statistical interaction can be assessed in one of two ways: In stratification, treatment effects are assessed across subgroups defined by different baseline or demographic factors. In interaction modeling, the treatment and baseline or demographic factor are included with an interaction term in a statistical model (i.e. treatment + baseline factor + treatment * baseline factor).
Interestingly, the meaning of an interaction term depends on the model used. For continuous outcomes, in a linear regression model, the slope (or 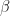
Importantly, the presence or absence of an interaction and its direction depends on whether interactions are tested using addition or multiplication. Brankovic and colleagues use a hypothetical example. Suppose a study finds the following treatment effects in women and men:
Women: A treatment effect was found in 1% of participants receiving treatment, and 3% receiving placebo
Men: A treatment effect was found in 2% of participants receiving treatment, and 4% receiving placebo
The interaction effects between placebo and treatment are different depending on whether effects are added or multiplied:
| Method | Effect in women | Effect in men |
|---|---|---|
| Risk difference |  |
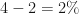 |
| Relative risk | 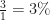 |
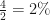 |
Many randomised controlled trials use logistic and Cox regression models, which will assess interactions using multiplication. However, additive effects are often preferred over multiplicative effects so that when treatment is allocated to the subgroup that benefits the most, this increases the overall benefit. Others have also argued that showing an additive effect of treatment across subgroups may provide stronger evidence for biological interaction.
For binary outcomes, Brankovic and colleagues expand further on how to test multiplicative and additive interaction effects in logistic and Cox regression models (see paper for details).
Interpretation and reporting statistical interactions
When treatment effects vary across subgroups with different baseline factors, this can be interpreted as effect-measure modification. Here, the baseline factor only needs to correlate with another factor that causes the outcome; it does not need to directly affect the outcome. Thus, treatment subgroup effects cannot be attributed to the baseline factor itself. The aim of effect-measure modification is to identify subgroups which will benefit the most from treatment.
An interaction can only be interpreted as causal if both the treatment and baseline factor directly affect the outcome. In this case, the aim of assessing causal interaction is to intervene on the baseline factor to improve the effect of treatment. In the example on balance exercise above, the aim would be to increase muscle strength in those who are weak, to improve the effectiveness of balance exercises for decreasing falls risk.
However, if confounding of the baseline factor on the outcome was not controlled for, it is not immediately possible to claim that the baseline factor is responsible for subgroup effects. This is because randomisation produces unbiased comparability of treatment and control groups, but does not account for imbalances between subgroups that affect the outcome. Some approaches to deal with this are to (1) stratify randomisation on known baseline factors that affect the outcome and (2) adjust for relevant factors by including them in the statistical model.
References
Brankovic, M, Kardys, I, Steyerberg, EW, Lemeshow, S, Markovic, M, Rizopoulos, D, Boersma, E (2019). Understanding of interaction (subgroup) analysis in clinical trials. Eur. J. Clin. Invest., :e13145.
