Matplotlib: data visualisation

In the short series on statistical inference, I ran simulations and plotted graphs to show distributions of raw data and statistics for repeated experiments. All simulations and plots were done with the programming language Python and its plotting library Matplotlib. What exactly are Python and Matplotlib, and how can these tools be used to visualise data?
Python is an open source, powerful programming language that, among other things, can be used to process and analyse data. Python’s functionality can be extended by importing libraries, which give access to additional functions. Matplotlib is a widely-used 2-dimensional plotting library that can produce publication-quality figures in a number of formats.
Installing Python and Matplotlib See this post for information on how to install Python and additional Python libraries commonly used in scientific computing.
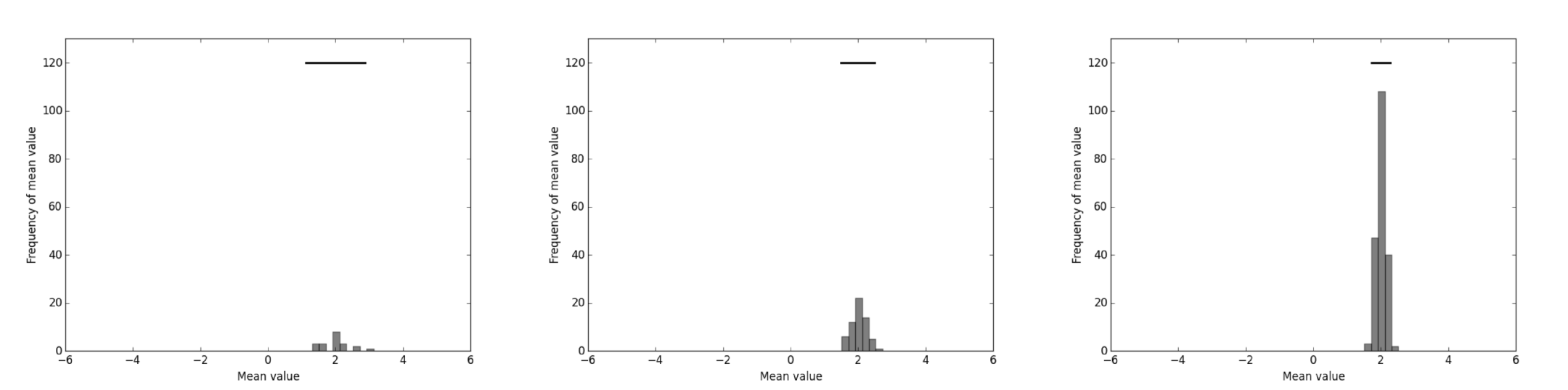
The following Python code defines a function called plot_ci to simulate continuous data in 2 groups, and plot the distribution of the mean and width of the 95% CI of the mean. If this is your first time reading Python code, read the following function to get the idea but don’t worry too much if you don’t understand everything. The comments (lots of statements starting with #) will help explain what the code is intended to do:
# Import the libraries needed to simulate and plot data
import random
import numpy as np
import matplotlib.pyplot as plt
# Include this command if running code in an ipython notebook
%matplotlib inline
def plot_ci(n):
"""
This function will simulate data from a continuous outcome in 2 groups,
calculate the between-group mean difference, plot a histogram of the
mean difference, and indicate 95% CI of the mean difference.
Parameters
----------
n: sample size of each group
Returns
-------
A histogram plot of the mean difference between groups, and
print sample size, 95% CI of the mean difference, and width of the CI.
"""
# Set a seed value so simulations of randomly-generated values are reproducible.
random.seed(1)
# Define parameters (i.e., sample mean, standard deviation, sample size) for groups 1 and 2.
mean1, mean2 = 0, 2
sd1, sd2 = 1, 1
# Assign the input parameter, sample size n, to sample size for each group.
n1, n2 = n, n
# Calculate parameters (i.e., mean between-group difference,
# standard error of the mean between-group difference) for statistical inference.
mean_diff = mean2 - mean1
se_diff = ((sd1**2 / n1) + (sd2**2 / n2)) ** (0.5)
# Calculate lower and upper limits of the 95% CI of the mean between-group difference.
ci_lower_limit = mean_diff - (1.96 * se_diff)
ci_upper_limit = mean_diff + (1.96 * se_diff)
ci_width = ci_upper_limit - ci_lower_limit
# Simulate data on the mean difference between groups with repeated experiments.
# For continuous data, the distribution of the *statistic* of the mean between-group
# difference follows a random, Normal (Gaussian) distribution where the mean
# between-group difference is the mean of the distribution, and the standard error
# of the mean between-group difference is the standard deviation of the distribution.
mean_distribution = [random.gauss(mean_diff, se_diff) for _ in range(n1 + n2)]
# Plot the distribution of mean between-group difference and show 95% CI width.
# Set the intervals for the histogram bins.
bins = np.linspace(-10, 10, 100)
# Plot a histogram showing the distribution of the mean between-group difference.
plt.hist(mean_distribution, bins, alpha=0.5, color='k')
# Plot a horizontal line showing width of the 95% CI.
plt.plot([ci_lower_limit, ci_upper_limit], [120, 120], color='k', linestyle='-', linewidth=2)
# Create titles for the x- and y-axes.
plt.xlabel('Mean value')
plt.ylabel('Frequency of mean value')
# Set the x- and y-scale of the plot.
plt.axis([-6, 6, 0, 130])
plt.show()
# Print out sample size, 95% CI and width of CI. Format the 95% CI and width values
# to be displayed as (floating point) numbers to 2 decimal places.
print('n:', n)
print('95% CI:', '{:.2f}'.format(ci_lower_limit), '{:.2f}'.format(ci_upper_limit))
print('CI width:', '{:.2f}'.format(ci_width))
We now have a function that uses information about sample size to perform a series of operations. Let’s call the function and tell it to perform these operations for group sizes of 10, 30 and 100:
# Plot histograms for groups of different sample sizes
for n in [10, 30, 100]:
plot_ci(n)
This code produces plots that make up the bottom panel in the figure we saw previously, reproduced here. I then paneled the separate figures in Inkscape. Pretty nifty, for not that many lines of code!