Within-group analyses cannot be used to make between-group comparisons

Many research questions investigate how outcomes change (over time) in response to different test conditions or treatments. Participants are randomised into groups to receive a test condition or treatment to make the groups comparable in every way except the test condition or treatment that is received. Consequently, comparing outcomes between groups allows us to understand how outcomes change under different conditions or treatments.
Assumptions. This post assumes you have a background understanding of power and sample size in research. For a refresher on these concepts, see here.
Instead of directly comparing between groups, researchers sometimes look within groups to see how an outcome changes after the test condition or treatment is applied. In a two-group study for example, researchers might separately test whether an outcome has significantly changed in Group A and Group B. An outcome may change from baseline to final measurement in Group A but not in Group B, and some researchers might conclude that the test condition or treatment was effective in Group A but not Group B.
The above procedure uses within-group tests (also called pre-post testing) to make between-group conclusions.
Although inherently problematic, such comparisons are reported in ~10-15% of clinical and biomedical research papers. In a methodology paper, Bland & Altman (2011) use simulated data to explain why pre-post tests are misleading.
They simulated 10,000 Group A and Group B pairs of pre-post data for a randomised trial comparing two groups of 30, where there was no real difference between groups. Approximately 40% of these pairs showed a significant pre-post difference in one group but not the other.
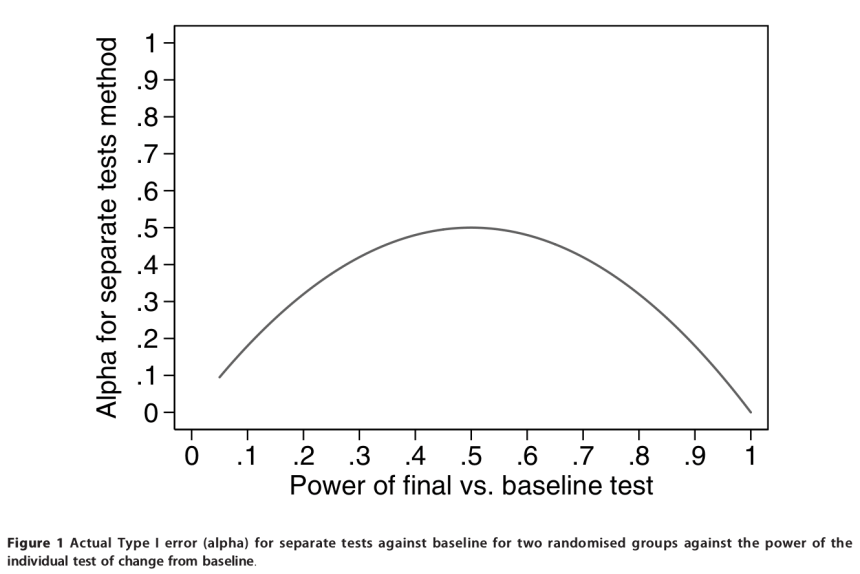
It turns out that what determines the proportion of pairs of tests with significant and/or non-significant differences is the power of the within-group tests. Figure 1, reproduced from the paper, shows the probability of finding a false positive (ie. the Type I error rate, or alpha) plotted against the power of the within-group tests. For a comparison between two randomised groups, as power of the within-group tests increases, the probability of finding a false positive (ie. concluding that the two groups are different based on within-group comparisons) can be as high as 50% (!) even though there is no real difference between groups. When a similar simulation is run for three randomised groups, the probability of finding a false positive can be as high as 75%.
Figure 1:
Summary
Within-group analyses cannot be used to make between-group comparisons. If this analysis is used when there is no real difference between groups, the probability of (falsely) concluding that there is a difference can be as high as 50%, much higher than the nominal 5% error rate. Use direct comparisons of outcomes between groups to determine whether there are between-group differences.
Reference
Bland and Altman (2011) Comparisons against baseline within randomised groups are often used and can be highly misleading. Trials 12:264.

can we compare % reduction in BMI between control group and study group after calculating mean % reduction in each groups
LikeLike
Yes that is possible, although for a randomised trial a better way is to determine the between group difference while adjusting for differences at baseline.
The point is that investigators have to calculate the difference between treatment and control groups to make inferences about the treatment, not examine differences within either group over time.
LikeLike