Why most published findings are false: the effect of p-hacking

In our previous post, we revisited the Ioannidis argument on Why most published research findings are false. Other factors such as p-hacking can also increase the chance of reporting a false-positive result. Such results are associated with a p-value deemed to be statistically significant, but the underlying hypothesis is in fact false.
Researcher degrees of freedom
As scientists, we have a great amount of flexibility when it comes to how we analyse and process our data. Some of this flexibility is removed when we conduct a clinical trial because the analysis plan has to be formally registered. However, data analysis for most other types of studies is flexible. This means researchers have to make decisions about what data to keep and reject, how to group and present data, whether a mean or trimmed-mean will be computed, whether the peak-to-peak amplitude will be reported or the area under the curve, etc.
There is also flexibility with statistical tests. Are we going to incorporate all conditions, or are we going to group two of them? What type of post-hoc tests are we going to use after running our analysis of variance? Would it be better to try a non-parametric test?
Simmons et al. (2011) demonstrated that, with so many degrees of freedom, researchers can generate statistically significant results from just about any data set. While some of these data processing decisions are well founded, others are erroneously believed to be correct, and are influenced by our human biases.
These researcher degrees of freedom influence published results and lead to a disproportionately large number of published p-values to be just below the traditional threshold of 
p-hacking.
In their paper, Simmons et al. (2011) demonstrated that if researchers always pick the more favourable choice, i.e., the one that favours finding a statistically significant result,
P-hacking in the context of the Ioannidis argument
Let’s revisit our recent post on the Ioannidis argument (i.e., most published research findings are likely false) and see how p-hacking influences the results.
In a research area that generally focuses on discovering novel results, approximately 10% of tested hypotheses might in fact be true. If we consider 1000 hypotheses, 100 of these will be true and 900 will be false. If studies in this area have adequate statistical power (i.e., 80%), 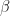
However, rather than using the conventional

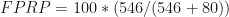
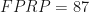
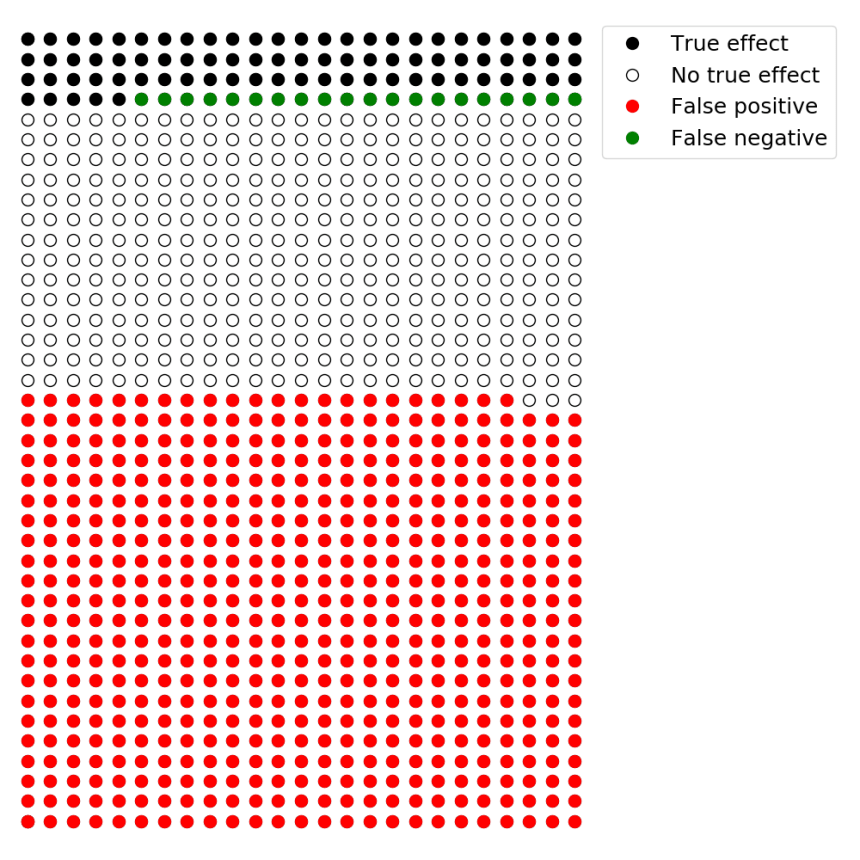
With beta = 20%, 80% of the hypotheses that are true will be statistically significant (i.e., true positives). With 100 true hypotheses, 80 of them will be found to be statistically significant. Given that p-hacking can artificially increase alpha to as high as 0.607, in this extreme case 60.7% the hypotheses that are false will be statistically significant. This means there will be 546 false-positive findings. Thus, the false-positive report probability will be 87%.
Summary
Some have argued that you can report anything as significant. While this is an extreme and bleak view of the situation, recent research is confirming that many results are not reproducible.
An important first step to reverse this harmful trend is to properly understand basic statistical concepts. Statistical power, type I and type II errors, p-values and percentage of true hypotheses all influence the chance that a statistically significant result reflects a true difference. A better understanding of these concepts can help researchers better plan and interpret their results.
Reference
Ioannidis JP (2005). Why most published research findings are false.. PLoS Med 2:e124.
Simmons JP, Nelson LD, Simonsohn U (2011). False-positive psychology: undisclosed flexibility in data collection and analysis allows presenting anything as significant. Psychol Sci 22:1359-66.
