Importing Spike2 data into Python

NOTE: I encountered trouble loading Spike2 .srm files with the neo package. Therefore, I coded a python package called spike2py that works well and has been used to analyse data from several studies at this point. Please see this post and the linked documentation for more information. Marty Oct 22, 2021
Spike2 is a piece of software written by the folks at CED (Cambridge Electronic Design) to collect data with their data acquisition boards. As pointed out in a previous post, Spike2 can be used to analyse data. However, the drop-down menus and options make it difficult to ensure processing is consistent from session to session. Spike2 comes with its own programming language, but it is not intuitive and also somewhat limited. Thus, many scientists choose to collect their data with Spike2, but process their data in another programming language such as Matlab or Python.
How do we get Spike2 data into Python? In our previous post, we saw how we could export our Spike2 data into a Matlab format (filename.mat) and import this file into Python. While this method works well, it does require us to use Spike2 to export all our data files into a Matlab format. This also means that we will have double the amount of data: the original Spike2 .smr file and the exported .mat file.
To address the two limitations of the previous solution, we will now learn how to use the neo Python package to directly read Spike2 .smr files.
The neo package
Neo is a package for analysing electrophysiology data in Python, together with support for reading a wide range of neurophysiology file formats. The package can be installed using pip install neo. The package depends on two other packages: quantities and numpy.
Important! When neo is installed using pip, version 0.5.2 is installed. This is the version I used in the current blog and accompanying code. Unfortunately using the newest version (0.6.1) caused the current code to not work. As a work around, I have include the neo package for version 0.5.2 here. I will look into getting the code to work with version 0.6.1 and post a revision when I have figured out the issue.
Personally, I run Python via Anaconda, a free and open source distribution of Python for data science. Anaconda comes with many of the packages that data scientists use on a daily basis, and it offers an easy mechanism to install new packages. Having said that, neo could not be install via Anaconda, so I downloaded the .tar.gz file, extracted the files and copied the neo folder to ~/anaconda3/lib/python3.6/site-packages/. This worked on my Linux computer, but the location may be slightly different on a Windows or Mac computer.
Using the neo package to load Spike2 files
Now we will learn how to use the neo.io.Spike2IO function to read our data in Python. The basic approach is to create a reader object and then read in the block of data.
import neo
import numpy as np
# create a reader
reader = neo.io.Spike2IO(filename='data.smr')
# read the block
data = reader.read(cascade=True, lazy=False)[0]
If we type data on the Python command line after running this code, we see:
Block with 1 segments
name: 'One segment only'
# segments (N=1)
0: Segment with 4 analogsignals
annotations: {'ced_version': '3'}
# analogsignals (N=4)
0: AnalogSignal with 1 channels of length 217741; units dimensionless; datatype float32
name: "b'Flex'"
annotations: {'channel_index': 0,
'comment': b'No comment',
'physical_channel_index': 0,
'title': b'Flex'}
sampling rate: 5000.0 Hz
time: 0.0 s to 43.5482 s
1: AnalogSignal with 1 channels of length 217741; units dimensionless; datatype float32
name: "b'Ext'"
annotations: {'channel_index': 1,
'comment': b'No comment',
'physical_channel_index': 1,
'title': b'Ext'}
sampling rate: 5000.0 Hz
time: 4.9999999999999996e-05 s to 43.54825 s
2: AnalogSignal with 1 channels of length 21774; units dimensionless; datatype float32
name: "b'Angle'"
annotations: {'channel_index': 3,
'comment': b'',
'physical_channel_index': 3,
'title': b'Angle'}
sampling rate: 500.0 Hz
time: 9.999999999999999e-05 s to 43.548100000000005 s
3: AnalogSignal with 1 channels of length 21774; units dimensionless; datatype float32
name: "b'triangle'"
annotations: {'channel_index': 6,
'comment': b'',
'physical_channel_index': 6,
'title': b'triangle'}
sampling rate: 500.0 Hz
time: 0.00015 s to 43.54815 s
Wow! That is a lot of information. It is a good idea to read the neo documentation if you want to learn more about how data is imported. Our current block of data contains 4 analog signals. We can see that the name of the first analog signal is b'Flex, it was channel index number 0 when it was recorded in Spike2, it was sampled at 5000Hz, and contains data from 0 to 43.5482 s.
Extracting time index and data from neo data objects
The people who created neo have included many functions that can be used with this type of imported data. However, I prefer to take full control of my data processing and would prefer to simply have an array of numerical values that correspond to sample times and data values.
I decided to create separate Python dictionaries for each channel of data. Each dictionary will contain the sample times, data, and sampling rate associated with a given channel. I already know that I have 4 channels named Flex, Ext, Angle and triangle, so initialize 4 dictionaries and add the desired channel information.
flex = {}
ext = {}
angle = {}
triangle = {}
for i, asig in enumerate(data.segments[0].analogsignals):
# Extract sample times
times = asig.times.rescale('s').magnitude
# Determine channel name, without leading b'
ch = str(asig.annotations['title']).split(sep="'")[1]
# Extract sampling frequency
fs = float(asig.sampling_rate)
# Assign sampling times, sampling frequency and data to correct dictionary
if ch == 'Flex':
flex['times'] = times
flex['signal'] = np.array(asig)
flex['fs'] = fs
flex = signal_proc.emg_proc(flex)
elif ch == 'Ext':
ext['times'] = times
ext['signal'] = np.array(asig)
ext['fs'] = fs
ext = signal_proc.emg_proc(ext)
elif ch == 'Angle':
angle['times'] = times
angle['signal'] = np.array(asig)
angle['fs'] = fs
angle = signal_proc.tremor_proc(angle)
elif ch == 'triangle':
triangle['times'] = times
triangle['signal'] = np.array(asig)
triangle['fs'] = fs
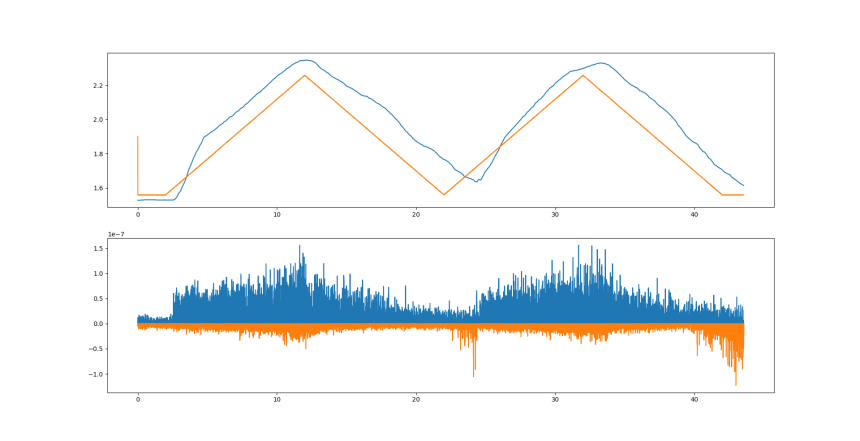
It is also a good idea to plot our data to make sure it is what we expect. After running some basic processing on the data, we can generate the following figure with the angular data of wrist flexion-extension and the triangle target participants had to follow, and the muscle activity in the wrist flexor and extensor muscles.
The data file (data.smr) and code used in the present example (including the basic processing and plotting functions) (spike2_python.py) are available here.
Summary
We learned how to use the neo package to directly import Spike2 .smr files into Python. While the neo data format is a little complex and field-specific, it was relatively easy to extract the data we needed and use dictionaries and numpy arrays.

Seems Neo has a new implementation using non-opensource API (sonpy):
reader = neo.rawio.CedRawIO(filename=file)
reader.parse_header()
print(reader)
see https://github.com/NeuralEnsemble/python-neo/pull/987
…
LikeLike
Hello,
I have just tried this but I get an erro:
TypeError: read_block() got an unexpected keyword argument ‘cascade’
Can you help?
Best wishes
Andrew
LikeLike
Hi Andrew, I too have had trouble with neo and reading directly from Spike2 files.
That is why I coded Spike2py, a Python package that you can install with pip install spike2py. note that you will need to export (batchexport) your spike2 files to .mat format; all this id explained in detail on the documentation site of spike2py.
If you search for spike2py on our blog, you will will find a relatively recent post outlining how to use it. Also, the github and pypi pages for spike2py provide a brief overview and link to the more detailed instructions.
Let me know if you run into any trouble with spike2py.
LikeLike
For anyone interested, I have made a module to help analyse data collected in Spike2 using Python. I can be found here on GitHub.
Because of issues trying to open Spike2 files directly in Python, the module assumes the data has been exported to .mat files (Matlab files). A script is provided that will allow bulk-export.
A dedicated webpage provides some tutorials on how to use the module, as well as the API for the various components of the module.
I have not yet incorporated spike-related signals (primarily because I did not need them at the time I was coding the module), but I have plans to include these when I get a bit more time, or I actually need them for my own work.
LikeLike
Hi Eduarda, sorry to hear you are having trouble loading your data. I have not used Python to analyse spike/wavemark data yet, but I am happy to learn.
First, do you care about the actual spike templates or do you simply want to firing times?
Also, is the channel you want (i.e. 16 nw-10) a sub-channel of the initial wavemark channel? From sorting motor units in the past, I vaguely remember something about being able to split the various spikes/templates into individual channel. I also remember that when I exported the data to .mat, I would have to change one of the setting from the Export window so that wavemark channels were outputed as spike times. I think it was possible to actually export the wavemark channels as templates and open them in Matlab, but it has been many years since I looked into this.
While it is not an elegant solution, I tend to resort to exporting Spike2 data to .mat and then opening the files with the io module. This is what Jo presented in a previous post (https://scientificallysound.org/2016/12/26/file-inout-how-to-import-data-files-from-spike2-and-matlab-into-python/). Coincidently, I am currently writing a Python package that provides various tools to import and process Spike2 data that has been exported to .mat. It is mostly for my own use, but would be happy to share it if it could be of use. It does not have functionality for every type of signal yet (e.g. wavemark), but I am sure I could figure it out and add it.
My guess is that exporting your data to .mat would give you access to the data you want. There is a script offered by CED that allows all .smr files in a folder to be saved to .mat, but I am not sure what the default behaviour is for wavemark channels. Alternatively you could create your own script, which is make easier by turning on the script recording option, opening, exporting and closing a file, and then have Spike2 generate a script of those actions. You can then have the script run on all your files (although I am not very good at Spike2 scripting, so I would not help you with this step).
Let me know how you go. Try exporting to .mat and see if your channel is there. If you have trouble, I am happy to have a play with it when I get a bit of free time; simply send a link to an example file (you can export a portion of a Spike2 file to .smr; that way you don’t have share a full trial; 10s would be fine). Also, I am happy to share my Python Package to work with Spike2 files exported to .mat; but it still a work in progress…
Marty
LikeLike
Hey, so I tried to use this script to read some data from .smr files of neuronal activity and singing of my birds, it worked fine for the raw data, recognizing and channels and etc.
However, we have one extra ‘channel’ called ’16 nw-10′ that contains spikes templates (chunks of spikes), with little parts that we would like to be put together, but it was not recognized by this code, even when we got an .smr of only this channel.
Probably is something about how the read command works, would you have any ideas how to help us?
thanks in advance.
Eduarda
LikeLike
Sorry for the extremely late reply. You likely found a solution. But in future, you might want to try my spike2py Python package; I wrote it to get around the various issues I was having with neo and loading .smr files directly. You can find spike2py explained in a post on this blog, or on github and pipy. You can simply pip install spike2py to install it.
LikeLike