The impact of statistical power on effect size estimates

In a previous post, we saw that the number of subjects or samples in our study does not influence the rate of false-positive findings. In this post we will learn how sample size influences estimates of the size of studied effects.
If the true effect of a medication is to reduce heart rate by 10 beats per minute, how well do we estimate the effect if we recruit only a handful of study participants? What if we include a large number of participants? Will we overestimate the size of the effect? Will we underestimate it?
Creating two populations for our simulations
Let’s create two populations with known parameters. For our example, we will create one population with mean = 0 and standard deviation = 1 and another population with mean = 0.5 and standard deviation = 1.
We have two populations that, on average, differ by 0.5 and have the same amount of variability. Therefore, the size of the true effect is 0.5. Also, for those who read one of our previous posts, Cohen’s d would also be 0.5, a moderate effect. The two populations are plotted below:

P-values from tens of thousands of studies
When we carry out our research, we don’t usually have access to all individuals of a population. We therefore take a sample from a population and use statistics to test our chosen hypothesis and estimate various measures.
In our current example, we will carry out a simulated study by sampling individuals from the first population and individuals from the second population. Next, we will run an independent t-test to test whether the two samples are different, remembering that the null hypothesis is that there is no difference between our two samples. Our t-test will return a p-value. We can also estimate the size of the true population effect (which we know to be 0.5) by calculating the difference between the means of our two samples.
In our example, we will conduct 10000 of these simulations, and this will be repeated with sample sizes of 5, 10, 25, 50, 100 and 1000.
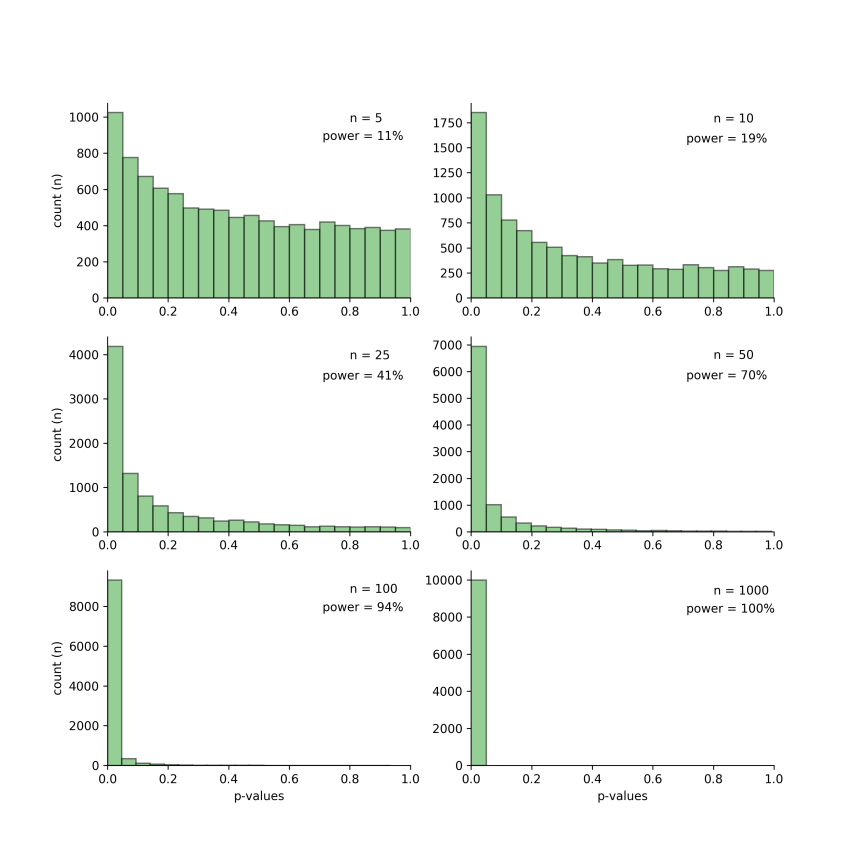
Below are the p-value results for these simulations. In each subplot, the x-axis represents the p-value obtained for the simulations and the y-axis the count. The left-most bin contains all p-values between 0 and 0.05, the p-values that reach the traditional level of significance.
The sample size and the associated statistical power are indicated in each of the subplots. For example, the top-right subplot shows the results when the sample size is 10. In this case, the statistical power is only 19%. While there are over 1750 p-values below the traditional threshold of 0.05, all other simulated studies generated p-values that were greater than this threshold and would be considered non-significant.
Note that as sample size increases, statistical power increases. This is accompanied by an ever increasing number of simulated studies having p-values below the threshold of 0.05.
Effect size estimates from studies reaching significance
It has been reported that many studies are grossly underpowered. For example, the median statistical power in neuroscience studies was estimated to be 20%. This means that many studies will result in false-negative results. In our example, this corresponds to all the p-values that are not in the left-most bin in the plots above.
The bias to publish significant results means that the majority of false-negative results are not published. Only those that are lucky enough to be in the left-most bin, with p-values smaller than 0.05, are published.
But does the statistical power and resulting p-value of a study influence effect size estimates?
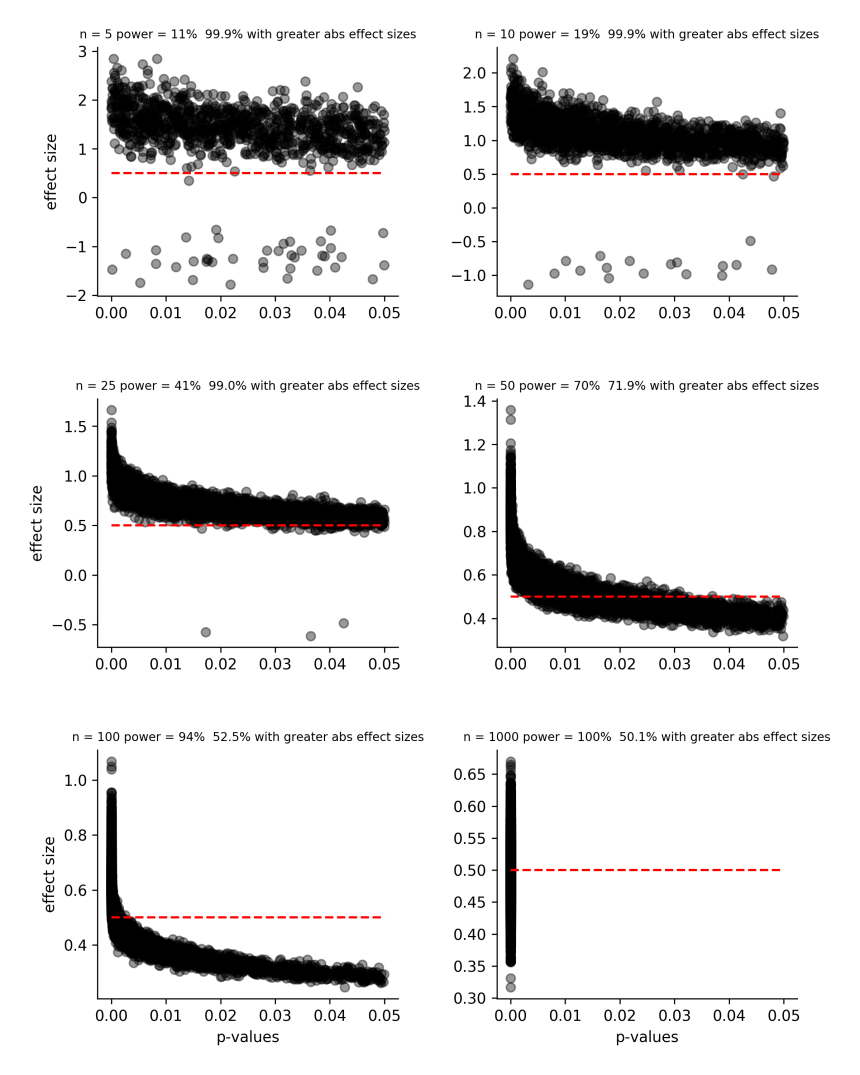
The figure below shows the relationship between significant p-values (those below 0.05) and effect size estimates (the difference between the means of both groups). Each grey data point represents the reported effect size from one of the 10,000 simulated studies.
Each subplot corresponds to the simulations for a given sample size. Also indicated is the associated statistical power and the percentage of studies that overestimate the size of the true effect. The red dashed lines indicates the true size of the studied effect.
As we can see, underpowered studies tend to overestimate the size of the true effect, especially for small p-values. For example, when 10000 simulations were carried out with a sample size of 25, statistical power was 41% and, of studies with significant p-values, 99% of them overestimated the true effect size of 0.5.
Note that as sample size increases, the percentage of studies that overestimate the true effect size decreases. Also, by looking at the y-axis range of each subplot, we can see that the magnitude of these estimation errors decreases as sample size increases.
Summary
Effect size estimates will tend to be overestimated in studies with low to moderate statistical power. Importantly, this overestimation will be worse for highly (statistically) significant results; those with very small p-values. This may seem somewhat counter intuitive.
Thus, we must be wary of highly significant results from small studies. One possibility is that these studies are sufficiently powered because the true effect is large. The other, more likely possibility, is that the true effect is small or moderate and its magnitude is being overestimated by these underpowered studies.
Reference
Curran-Everett D (2017). Minimizing the chances of false-positives and false negatives. J Neurophysiol 122, 91-95.

Would you mind sharing your example codes?
LikeLike
Certainly! I have uploaded the file to github
LikeLike