What are degrees of freedom in statistics? – Part 2

In a previous post we saw that t distributions with more degrees of freedom approximate the Normal distribution more closely, and degrees of freedom are increased by testing more subjects. How do degrees of freedom influence t values when calculating confidence intervals?
The confidence interval about an effect indicates how the effect varies if the study is repeated many times. For example, if we found that beer was better than vodka at reducing pain response by 4 points (95% CI 2-6 points) on a 10 point scale, this means subjects who drank beer experience 4 points less pain on average compared to those who drank vodka. If the study was repeated many times, on average, subjects who drank beer would experience as low as 2 points less pain to as high as 6 points less pain 95% of the time. So confidence intervals indicate how precise an estimate is. If we had only tested 5 instead of 30 subjects, we might have found beer reduced pain response by 4 points (95% CI 0-8 points) compared to vodka. Here, on average, subjects who drank beer would experience as low as 0 points less pain to as high as 9 points less pain 95% of the time. Since the 95% CI crosses zero, there is no difference between beer and vodka. But the wide 95% CI shows the estimate of the effect of beer vs vodka on pain is very imprecise.
When calculating confidence intervals about an effect (eg. a mean between-group difference), we use the sampling distribution and a standard score to tell us where the effect falls in the sampling distribution. For a Normal distribution, this standard score is known as the z score:
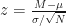
with sample mean 
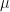
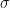

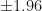
Using the z score to calculate a 95% CI requires knowing the population variance 
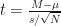
Both z and t will vary from sample to sample, since
import numpy as np
import scipy.stats as st
import matplotlib.pyplot as plt
# generate an array of linearly spaced values between -5 and 5
x = np.linspace(-5, 5, 1000)
# generate a list of different degrees of freedom
dof = [2, 5, 29]
colors = ['b', 'g', 'r']
subplot = [1, 2, 3]
# specify typical stats parameters: Type I error rate of 5% for a two-tailed test
alpha = 0.05
ntails = 2
plt.figure()
ymax = 0.1
for d, color, s in zip(dof, colors, subplot):
# plot the probability density function of the Normal distribution over x
plt.subplot(3, 1, s)
plt.plot(x, st.norm.pdf(x), 'k', linewidth=4, label='norm')
# calculate the z value for 95% CI cut-off and plot the lower and upper limits
zvalue = abs(st.norm.ppf(alpha / ntails))
plt.plot([-zvalue, -zvalue], [0, ymax], 'k', linewidth=4)
plt.plot([zvalue, zvalue], [0, ymax], 'k', linewidth=4)
# plot the probability density functions of t distributions over x, for different dof
plt.plot(x, st.t.pdf(x, d), color=color, linewidth=2, label='t (df={:.0f})'.format(d))
# calculate the t value for 95% CI cut-off and plot the lower and upper limits
tvalue = abs(st.t.ppf(alpha / ntails, d))
plt.plot([-tvalue, -tvalue], [0, ymax], color=color, linewidth=2)
plt.plot([tvalue, tvalue], [0, ymax], color=color, linewidth=2)
# set other figure settings
plt.xlim(-5, 5)
plt.ylim(0, 0.45)
plt.locator_params(axis = 'y', nbins=5)
plt.ylabel('P(x)')
plt.xlabel('x')
plt.legend(prop={'size':10})
plt.savefig('figure2.png', dpi=300)
Figure 1: Simulation of how t values from t distributions with 2, 5 or 29 degrees of freedom approximate the z score from a Normal distribution, for a 95% cut-off. t values from t distributions with greater degrees of freedom approximate the z score more closely. t values and z scores are indicated by vertical lines.

The width of the confidence interval is determined by the margin of error. The margin of error is determined by the t value or z score, and the size and variability of the effect. Narrow confidence intervals indicate precise estimates of effect, and are obtained when t values are small. Small t values are obtained as the t distribution approximates the Normal distribution when sample size is large.
Summary
For a 95% cut-off, t values approach z scores when sample size is large. If sample size is small, use the t value from the appropriate distribution, depending on degrees of freedom, to calculate 95% CI.
Reference
Cumming and Calin-Jageman (2017) Introduction to the new statistics: Estimation, open science, & beyond. Routledge: New York. p 105.
