Research concepts: Confidence interval of a mean

In previous posts, we learned that the aim of statistics is to extrapolate properties of samples to make inferences about population. However, random variation in individuals in the population produces sampling error, which means a single sample may not accurately reflect properties of the population. When data are binary, we learned how the 95% confidence interval (CI) of a sample proportion is used to estimate and infer the population proportion. Next, when data are continuous, we learned how to calculate the mean of the sample data, and quantify variability of Normally distributed data using the standard deviation.
In this post we are going to learn how to use this information to calculate the 95% CI of a mean and estimate the population mean?
Calculating the 95% CI of a mean
The CI of a mean is calculated from 4 values:
- Sample mean. The CI is centered about the sample mean, which is our best estimate of the population mean.
- Sample standard deviation (SD). If the data are highly variable and scattered (SD is large), the precision of the estimate of the population mean will be lower. Thus, the width of the CI are proportion to the sample size.
- Sample size. Having more samples helps to estimate the mean more precisely, and so provides more confidence about our estimate of the population mean. Thus, the width of the CI is inversely proportional to the sample size. Specifically, to halve the width of the CI will require four times the number of samples, so the width of the CI is inversely proportional to the square root of the sample size.
- Degree of confidence. CIs are usually calculated for 95% confidence, but any value can be used. 99% CIs will provide more confidence but produce wider intervals. Conversely, 90% CIs provide less confidence and produce narrower intervals.
Determining the 95% CI involves calculating the sample mean and the margin or error (i.e. half the width of the CI) on either side of the mean. We learned how to calculate the margin of error when conducting independent t-tests in Python. Briefly, the margin of error is calculated as:
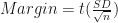
Where 
Figure 1 shows body temperatures from 3 samples of different sizes, the means and 95% CI, and histograms of the data for each sample:
Figure 1: Body temperature data from samples of size 10 (row 1), 30 (row 2) and 100 (row 3). Plots show individual subject data and means (95% CI) (column 1) and histograms of the data (column 2). It is clear that the width of the 95% CI decreases as sample size increases.

Interpreting the 95% CI
For the sample of size 30 (row 2), the mean (95% CI) body temperature is 36.91 (36.80 to 37.02) deg C. If 95% CI from many samples of 30 subjects were calculated, we would expect the CIs to include the mean population body temperature in ~95% of the samples. Thus, we interpret this finding as: the mean body temperature is 36.91 deg C, and we are confident that 95% of the time, the mean varies from 36.80 to 37.02 deg C.
Important assumptions
The sample is representative of the population. That is, the sample was randomly selected from the population.
Observations are independent. That is, data from one individual does not influence data from another individual. In our example, this assumption would be violated if body temperature was measured more than once for any individual, or if individuals were siblings.
Data are accurate. That is, data are measured correctly.
The population is distributed Normally. This assumption matters more when sample size is small.
95% CI of a mean difference
This post calculates the 95% CI about a mean statistics of a group of individuals. Often, we might want to compare differences between two or more groups. In that case, we are interested in the CI of a mean difference. The principles above also apply to calculating the between-group mean difference and 95% CI. Likewise, as shown in a previous statistics note, the 95% CI about a between-group mean difference also decreases as sample size increases.
Summary
We simulated continuous data of body temperature to show sample means and their 95% CI. We interpreted the means and learned how 95% CI are used to estimate the population mean.
Reference
Motulsky H (2018) Intuitive Biostatistics. A Nonmathematical Guide to Statistical Thinking. 4th Ed. Oxford University Press: Oxford, UK.
